สวัสดีครับทุกคน สำหรับบทความนี้ก็เป็นบทความเฉพาะกิจหน่อย สถานการณ์ปัจจุบัน (24 มีนาคม 2563) ค่อนข้างน่าเป็นห่วงพอสมควรเลยครับ อยากให้ทุกคนรักษาสุขภาพกันให้มากๆนะครับ
สำหรับบทความนี้ตามหัวข้อเลยคือเราจะมาลองทำนาย covid 19 ด้วยข้อมูลจากแผ่นฟิล์ม x-ray ครับ
ก่อนอื่นขออภัย ณ ตรงนี้ก่อนว่าผมไม่ได้เป็นผู้มีความรู้ด้านการแพทย์ครับ เลยคิดว่าเขียนๆไปอาจจะมีส่วนใดส่วนนึงบกพร่องไปบ้าง ถ้าใครมีความรู้หรือรายละเอียดอะไรเพิ่มเติมสามารถบอกได้เลยครับ
และตัว model ที่ทำการสร้างในครั้งนี้สร้างขึ้นเพื่อศึกษาในเชิงวิศวกรรมมากกว่าที่จะนำไปใช้งานจริงครับ
บทความนี้ก็ได้รับแรงบันดาลใจมาจากบทความต่างประเทศของเว็บบล็อค pyimagesearch ถ้าใครสนใจอยากอ่านเวอร์ชันของต้นทางสามารถเข้าไปดูได้ที่นี่ครับ https://www.pyimagesearch.com/2020/03/16/detecting-covid-19-in-x-ray-images-with-keras-tensorflow-and-deep-learning
อนึ่ง ไลบรารี่ที่ผมจะใช้ในทีนี้คือ PyTorch ซึ่งจะไม่เหมือนกันกับของต้นทางที่ใช้ tensorflow ครับ
1.หาข้อมูล
ผมต้องการข้อมูลอยู่ 2 อย่างคือภาพฟิล์มที่พบว่าติดเชื้อและไม่ติดเชื้อ ภาพที่ติดเชื้อผมจะขอเรียกว่า positive ส่วนไม่ติดเชื้อจะขอเรียกว่า negative ครับ
ส่วนของภาพ positive ผมได้ภาพมาจาก github repo นี้ที่มีคนรวบรวมภาพฟิล์ม x-rays ของคนที่ติดเชื้อชนิดต่างๆไว้ https://github.com/ieee8023/covid-chestxray-dataset
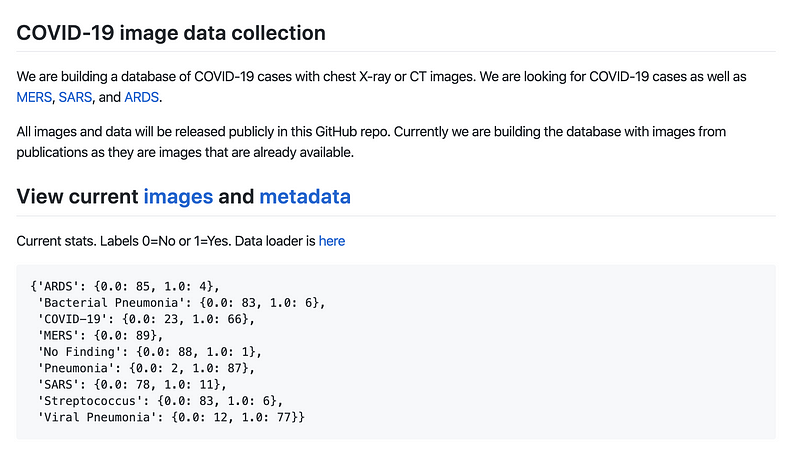
เนื่องจากภาพที่มีให้มีเฉพาะ sample ที่เป็น positive ผมเลยต้องไปหาเว็บไซต์ที่มี sample negative มาด้วย โดยผมได้ภาพที่ negative มาจากเว็บไซต์ kaggle

ในเว็บ kaggle เคยมี challenge นึงที่ให้ตรวจปอดบวมจากฟิล์ม x-ray มาก่อนครับ ผมเลยไปหยิบเอาภาพฟิล์มที่เป็น negative(ปกติ ไม่ปอดบวม) มาด้วย
2.จัดระเบียบ
การจัดระเบียบที่ผมต้องการก็ไม่ซับซ้อนมากครับ ผมต้องการที่จะมีโฟลเดอร์ 1 โฟลเดอร์ที่ไว้ใช้เก็บ datasets ทั้งหมด ข้างในมี subfolder ที่เก็บภาพ negative และ positive อย่างละโฟลเดอร์
เราจะมาเริ่มเอาภาพที่ negative ไปเก็บใส่โฟลเดอร์ก่อนimport os
from shutil import copyfile
from tqdm import tqdmpics = os.listdir('chest_xray/test/NORMAL')src = 'chest_xray/test/NORMAL'
dest = 'datasets/negative'
for idx, filename in enumerate(tqdm(pics), 0):
copyfile(os.path.join(src, filename), os.path.join(dest, str(idx)))
if idx == 67:
break
โค้ดที่ใช้ไม่ได้ซับซ้อนมากครับ แค่ย้ายภาพจากโฟลเดอร์ Normal ของ datasets ที่ kaggle ให้มาไปไว้ในโฟลเดอร์ที่เราต้องการเก็บ ผมจะ break ไว้แค่ 67 ภาพเนื่องจากว่า datasets ส่วนที่เป็น positive เรามีเพียง 67 ภาพครับ
สำหรับส่วนของ datasets ที่เป็น positive จะซับซ้อนกว่าเดิมเล็กน้อยเนื่องจาก data ที่ให้มามีหลายแบบหลายโรค เราจะต้องค้ดให้เหลือเฉพาะแบบที่เราต้องการคือเป็นโรค covid-19 และเป็นฟิล์มแบบ PA
ในทางการแพทย์เวลาเราถ่ายรูป x-ray ของปอดเราจะสามารถถ่ายได้หลายรูปแบบครับซึ่งจะใช้รูปแบบไหนก็จะขึ้นกับสถานการณ์ แบบที่เราจะใช้กันคือแบบ PA (ในการสร้างโมเดล) ซึ่งจริงๆแล้วยังมีอีกหลายแบบ แต่เนื่องจากผมไม่มีความรู้มากพอเลยจะขอข้ามเรื่องนี้ไปครับimport pandas as pd
import os
from shutil import copyfile
from tqdm import tqdmdf = pd.read_csv('covid-chestxray-dataset/metadata.csv')
df = df[df.finding == 'COVID-19']
df = df[df.view == 'PA']filenames = df[['filename']]src = 'covid-chestxray-dataset/images'
dest = 'datasets/positive'for idx, filename in enumerate(tqdm(filenames['filename'], 0)):
copyfile(os.path.join(src, filename), os.path.join(dest, str(idx)))
เพื่อความสะดวกผมจะข้อใช้ pandas อ่านไฟล์ metadata.csv แล้วจึงคัดเอาเฉพาะภาพที่ต้องการ ก่อนเอาไปเก็บลงในโฟลเดอร์ครับ
ไฟล์ metadata.csv ได้มาจาก github repos ที่เก็บภาพเอาไว้จะมีข้อมูลของภาพฟิล์มรวมถึงชื่อไฟล์ด้วย
ถ้ารัน code เสร็จแล้วเราก็จะได้โฟลเดอร์ที่มีภาพเก็บไว้ตามที่เราต้องการครับ

สำหรับบทความนี้ซึ่งเป็นตอนแรกที่เกี่ยวข้องกับการรวบรวมข้อมูลจะขอจบลงเท่านี้ครับ ถ้ามีข้อสงสัยหรือข้อเสนอแนะตรงไหนสามารถคอมเมนท์บอกได้เลยครับ ขอบุณมากครับ😊😊😊
ที่ผ่านมาผมไม่ได้มีแฟนเพจเฟสบุ๊คหรือช่องทางติดต่อที่ง่ายๆ เวลาคนมีปัญหาอะไรเลยอาจจะไม่สะดวกบ้าง ผมเลยเปิดแฟนเพจเฟสบุ๊คขึ้นมาครับ (พึ่งเปิดมาไม่นานเหมือนกัน) ก็ถ้าใครมีปัญหาหรืออยากปรึกษาเรื่องอะไรสามารถติดต่อได้ที่แฟนเพจเลยนะครับ สวัสดีครับ
ลิ้งค์แฟนเพจ