สำหรับบทความนี้เป็นตอนที่ 2 ต่อจากบทความที่แล้วที่เกี่ยวกับการเตรียมข้อมูลนะครับ ถ้าใครยังไม่อ่านตอนที่แล้วสามารถคลิกดูได้ที่ลิงค์นี้ครับ
อนึ่ง บทความนี้อาจจะจำเป็นต้องมีพื้นฐานเรื่อง deep learning หรือ pytorch มาบ้างก่อนนะครับ

ก่อนอื่นขออภัย ณ ตรงนี้ก่อนว่าผมไม่ได้เป็นผู้มีความรู้ด้านการแพทย์ครับ เลยคิดว่าเขียนๆไปอาจจะมีส่วนใดส่วนนึงบกพร่องไปบ้าง ถ้าใครมีความรู้หรือรายละเอียดอะไรเพิ่มเติมสามารถบอกได้เลยครับ
และตัว model ที่ทำการสร้างในครั้งนี้สร้างขึ้นเพื่อศึกษาในเชิงวิศวกรรมมากกว่าที่จะนำไปใช้งานจริงครับ
บทความนี้ก็ได้รับแรงบันดาลใจมาจากบทความต่างประเทศของเว็บบล็อค pyimagesearch ถ้าใครสนใจอยากอ่านเวอร์ชันของต้นทางสามารถเข้าไปดูได้ที่นี่ครับ https://www.pyimagesearch.com/2020/03/16/detecting-covid-19-in-x-ray-images-with-keras-tensorflow-and-deep-learning
อนึ่ง ไลบรารี่ที่ผมจะใช้ในทีนี้คือ PyTorch ซึ่งจะไม่เหมือนกันกับของต้นทางที่ใช้ tensorflow ครับ
เนื่องจากผมกะจะใช้ CNN มาทำเป็น model ประมวลผล เลยกินทรัพยากรเครื่องพอสมควร ผมเลยไม่ได้ทำการ train บน cpu ธรรมดาๆ หรือสร้าง model แบบ from scratch เลย
ในบทความนี้ผมเลยเลือกที่จะใช้ pre-trained model ที่มีมาให้ของ PyTorch ครับ ตัวที่ผมเลือกใช้ก็คือ ResNet18 (ถ้าใครมาลองทำตามแล้วอยากลองใช้ตัวอื่นแทนก็ได้ครับ)
ที่ใช้ pre-trained model เพราะว่าการมาเริ่มสร้างโมเดล CNN แบบ from scratch เป็นอะไรที่ยุ่งยากพอสมควรครับ บวกกับว่า datasets ที่เรามีค่อนข้างจะจำกัด เลยเลือกที่จะใช้ model ที่ train มาแล้วจะง่ายกว่า
แล้วผมก็ใช้วิธีการที่เรียกว่า transfer learning ในการทำโมเดลทำนายฟิล์มครับ
การสร้าง model ตัวนี้ผมเลือกที่จะอ้างอิงจาก best practice ใน document ของ pytorch เนื่องมาจากว่าการเขียน pytorch เนี่ยค่อนข้างจะยืดหยุ่น(บางทีก็เกินไป 😂) พอสมควร สามารถเข้าไปอ่าน doc ข้างล่างได้เลยครับ
1. Load ข้อมูล
เริ่มต้นจากโหลดข้อมูลที่เราเตรียมไว้มาก่อนครับ เนื่องจากว่า model ที่เราใช้เนี่ยเป็น model ที่ pretrain มาเราเลยจะต้องปรับข้อมูลให้เป็นเหมือนกันกับ model ต้นทางด้วยก่อนที่จะป้อนเข้าไป
2.สร้าง function train
ขั้นตอนนี้เราจะสร้างฟังค์ชันที่นำมาใช้เทรน model ของเราครับ
การทำ transfer learning จะมีหลักๆอยู่ 2 วิธีการ 1.คือการ Finetuning ให้ convnet ใหม่ 2.คือเอา convnet ตัวเดิมมาเป็น feature extracter แล้วเทรนใหม่แค่ layer สุดท้าย อ่านเพิ่มเติมได้ที่นี่ครับ
3.1 Finetuning ให้ convnet
ขั้นตอนนี้ก็จะต้องบอกว่าเราใช้ optimizer อะไร ใช้อะไรเป็น loss function บลาๆ ครับ
ตอนกดเทรนถ้าใช้ cpu train อาจจะนานหน่อย (อาจจะ 20 นาที+)
แต่ถ้าใช้ gpu จะไม่นานมากครับ
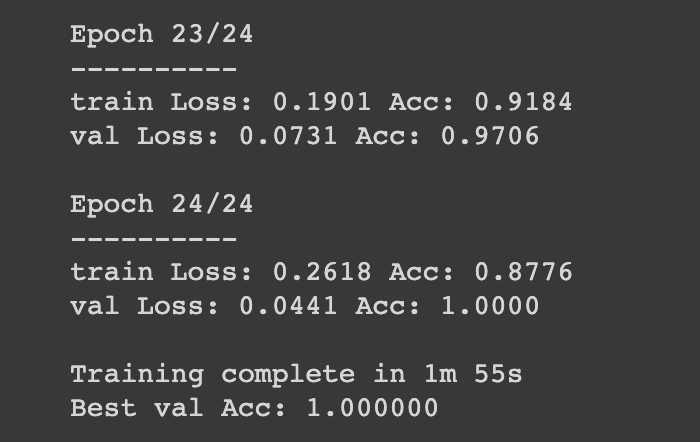
อันนี้ของผมตอนเทรนเสร็จ ค่า val Acc ดูแปลกๆหน่อย เดาว่าอาจจะมาจากที่ datasets ค่อนข้างน้อยครับ คิดว่าถ้ามีจำนวน datasets มาขึ้นน่าจะดู make sense มากขึ้น (อันนี้บวกกับผมไม่ค่อยเชี่ยวเรื่อง pytorch ซักเท่าไรด้วย ถ้าใครมีข้อเสนอแนะบอกได้เลยนะครับ)
3.2 ใช้ convnet เดิมเป็น feature extractor
วิธีนี้เราจะ freeze layer บนๆไว้แล้วมา train ใหม่แค่ layer หลังตอนเทรนก็จะเร็วขึ้นกว่าเดิมพอสมควร
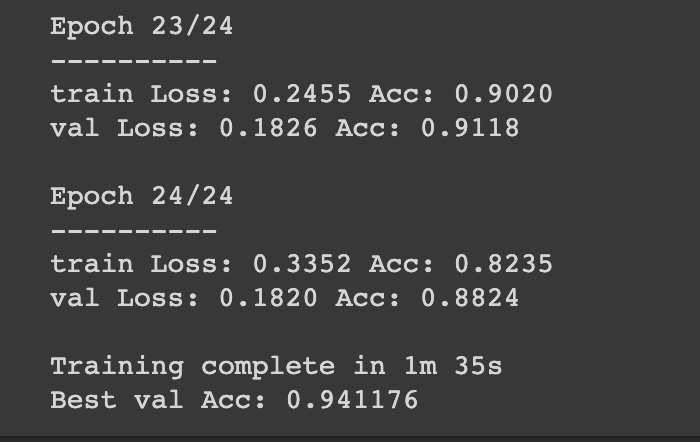
อันนี้เป็นผลลัพท์ที่ผมได้ครับ
จริงๆแล้วเรายังสามารถปรับปรุง model ได้อีกหลายอย่างเลยครับ ทำ visualizer ดีๆกว่านี้หรือลองเอา pre-trained ตัวอื่นมาลองดูก็ได้
ก็ถ้าใครสนใจอยากลองเล่นผมแปะลิงค์ github ที่ผมทำไว้ข้างล่างนะครับ