สำหรับบทความนี้เป็นสิ่งที่ผมคิดว่าน่าสนใจมากๆอย่างนึงครับ ในบทความนี้เราจะมาทำตัวตรวจจับ spam หรือ spam classifer กัน ซึ่ีอัลกอริทึมที่เราจะใช้สร้างเราจะมีความเกี่ยวข้องกับทฤษฎีทางคณิตศาสตร์ที่เรียกว่า ทฤษฎีบทของแบย์ส ครับ
เพราะฉะนั้นเดี๋ยวผมจะขอเริ่มอธิบายจากส่วนทฤษฎีก่อนแล้วกัน
ก่อนจะพูดถึงทฤษฎีบทของแบย์สต้องมีการกล่าวถึงความน่าจะเป็นแบบมีเงื่อนไขกันก่อน วิชาความน่าจะเป็นเบื้องต้นที่เราเรียนๆกันมาอาจจะไม่ได้มีเรื่องนี้อยู่ด้วย แต่ว่ามันเป็นอะไรที่น่าสนใจพอสมควรครับ
P(A|B) ถูกกำหนดให้เป็นความน่าจะเป็นที่จะเกิดเหตุการณ์ A ขึ้น ถ้าเกิดมีเหตุการณ์ B เกิดขึ้น ซึ่งจะสามารถคำนวนได้จาก ความน่าจะเป็นที่จะเกิดเหตุการณ์ A และ B พร้อมกัน หารกับความน่าจะเป็นที่จะเกิดเหตุการณ์ B
เข้าใจว่างง แต่ลองอ่านๆแล้วเท่าความเข้าใจช้าๆดูนะครับ
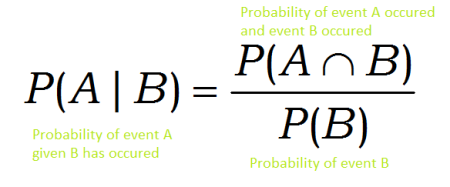
เมื่อเราเข้าใจความน่าจะเป็นแบบมีเงื่อนไขแล้ว เราสามารถนำความน่าจะเป็นแบบมีเงื่อนไขมาขยายความหมายออกไปได้อีก
ทฤษฎีบทของแบย์ส ทำให้เราสามารถคำนวณความน่าจะเป็นที่จะเกิดเหตุการณ์นึง โดยอิงมาจากอีกเหตุการณ์นึงได้
ปกติแล้วเราจะใช้คำนวณหาความน่าจะเป็นของเหตุการณ์ที่เราวัดได้ยากครับ โดยเราจะคำนวณได้จากเหตุการณ์อีกเหตุการณ์ที่เกี่ยวข้องกันแทน
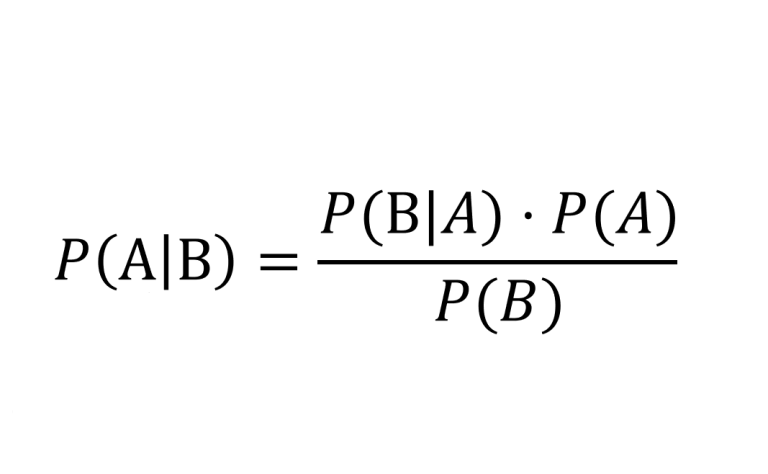
นำมาประยุกต์ใช้กับ Spam classifer
สมมติว่าผมมีประโยคยาวๆอยู่ประโยคนึง แล้วในประโยคนั้นก็ประกอบด้วยคำหลายคำ ผมต้องการอยากรู้ว่าประโยคของเราเนี่ยมันเป็น spam หรือเปล่า โดยผมตั้งสมมติฐานไว้ว่า คำแต่ละคำที่อยู่ในประโยคไม่ได้มีความเกี่ยวข้องกัน แล้วเราก็จะหาความน่าจะเป็นว่าถ้าคำนี้มันอยู่ในประโยคจะทำให้ประโยคนี้เป็นสแปม

ถ้านำทฤษฎีบทขอแบย์สมาประกอบจะทำให้เราสามารถคำนวณได้ว่า ความเป็นไปได้ที่ประโยคนั้นเป็นสแปมจะเท่ากับ พจน์ที่เหลือที่เราสามารถคำนวณได้ง่ายคูณกันตามสมการครับ
สำหรับใครที่อยากอ่านทฤษฎีโดยละเอียดสามารถเข้าไปอ่านที่นี่

เขียนโค้ดกันดีกว่า
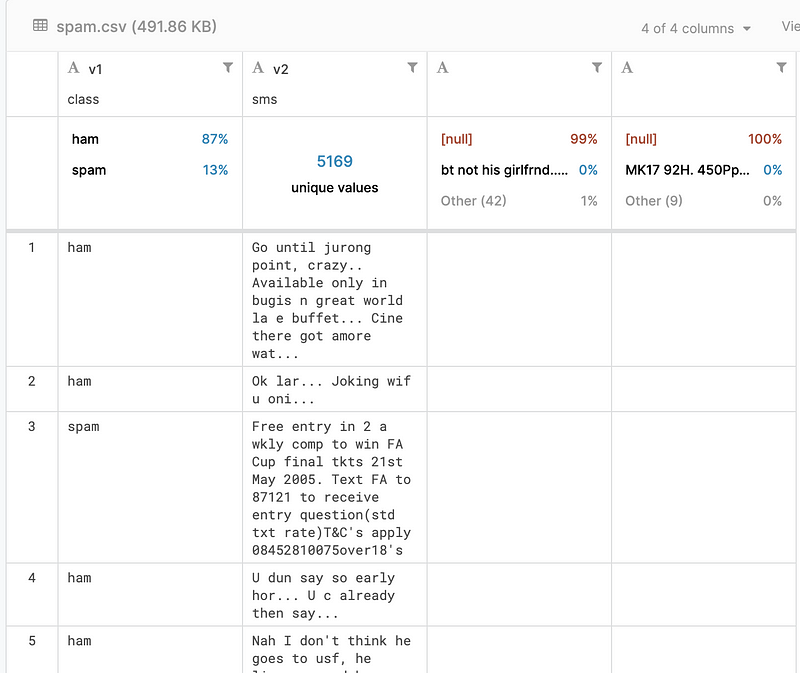
สำหรับบทความนี้ผมไปได้ datasets มาจาก kaggle ซึ่งมีคนรวบรวมข้อความ sms ไว้แล้วก็เขียนไว้ว่าข้อความแต่ละข้อความเป็นสแปมรึเปล่า
โหลดได้ที่ https://www.kaggle.com/uciml/sms-spam-collection-dataset
ในบทความนี้มีการใช้งานไลบรารี่ pandas และ sci-kit learn ถ้าใครยังไม่ติดตั้งสามารถติดตั้งได้ด้วยคำสั่ง
pip install <ชื่อแพคเกจ>
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_splitdata = pd.read_csv(“spam.csv”,delimiter=’,’,encoding=’latin-1')
data = data[[‘v1’, ‘v2’]]data = data.rename(columns={‘v1’: ‘class’, ‘v2’: ‘message’})
data.head()
4 บรรทัดแรกผมเริ่มต้นจากการ import ไลบรารีที่ใช้เข้ามา จากนั้นก็เป็นการเตรียมข้อมูล ผมเปลี่ยนชื่อคอลัมน์ของข้อมูลจาก v1 v2 เป็น class และ column เพื่อจะได้เรียกใช้ได้ง่าย จากนั้นก็แสดงผลข้อมูลออกมา
vectorizer = CountVectorizer()
vectorize_message = vectorizer.fit_transform(data[‘message’].values)
classifier = MultinomialNB()
targets = train[‘class’].valuesclassifier.fit(vectorize_message, targets)
ขั้นตอนนี้เราจะเรียกใช้ CountVectorizer จาก scikit-learn เนื่องจากเพื่อความง่ายในการคำนวณ คำแต่ละคำจะถูกแปลงไปเป็นข้อมูลที่เป็นตัวเลข
MultinomialNB จะทำหน้าที่คำนวณความสัมพันธ์ของคำแต่ละคำที่เรานำไปสอนตัวโมเดลของเราexamples = ["Bob ask you for a book?", “Free forex!”]
example_counts = vectorizer.transform(examples)
predictions = classifier.predict(example_counts)print(predictions)
ขั้นตอนนี้เป็นการนำโมเดลที่ได้มาทดสอบครับ ผมป้อนข้อความที่อยากทดสอบเป็น “Bob ask you for a book?” และ “Free forex!”
นำข้อความไปแปลงเป็นข้อมูลตัวเลข (เพราะเรา train โมเดลด้วยข้อมูลตัวเลข) จากนั้นก็สั่งให้ตัว model มันทำงาน

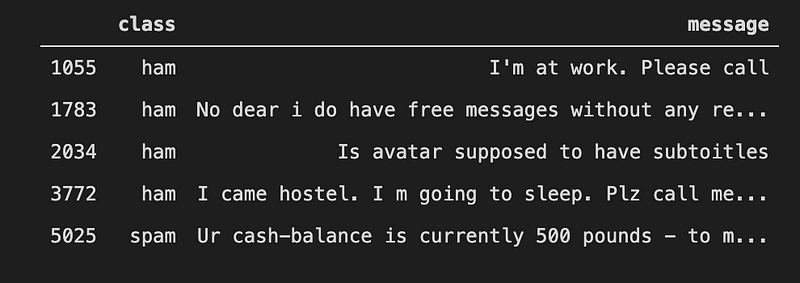
อันนี้เป็นผลที่ได้ครับ จะเห็นว่าประโยค Bob ask you for a book? ได้เป็น ham ซึ่งก็สมเหตุสมผล ส่วนประโยค Free forex โดนจัดเป็นสแปม ซึ่งก็ดูจะทำหน้าที่ได้ดีเลยครับ
ที่ผ่านมาผมไม่ได้มีแฟนเพจเฟสบุ๊คหรือช่องทางติดต่อที่ง่ายๆ เวลาคนมีปัญหาอะไรเลยอาจจะไม่สะดวกบ้าง ผมเลยเปิดแฟนเพจเฟสบุ๊คขึ้นมาครับ (พึ่งเปิดมาไม่นานเหมือนกัน) ก็ถ้าใครมีปัญหาหรืออยากปรึกษาเรื่องอะไรสามารถติดต่อได้ที่แฟนเพจเลยนะครับ สวัสดีครับ
ลิ้งค์แฟนเพจ